Приложение A: Продвинутые техники промптинга
Введение в промптинг
Промптинг, основной интерфейс для взаимодействия с языковыми моделями, представляет собой процесс создания входных данных для направления модели к генерации желаемого выходного результата. Это включает структурирование запросов, предоставление релевантного контекста, указание формата вывода и демонстрацию ожидаемых типов ответов. Хорошо спроектированные промпты могут максимизировать потенциал языковых моделей, приводя к точным, релевантным и творческим ответам. В противоположность этому, плохо спроектированные промпты могут привести к неоднозначным, нерелевантным или ошибочным результатам.
Цель prompt engineering заключается в последовательном получении высококачественных ответов от языковых моделей. Это требует понимания возможностей и ограничений моделей и эффективного донесения предполагаемых целей. Это включает развитие экспертизы в общении с ИИ путем изучения того, как лучше всего его инструктировать.
Данное приложение детально рассматривает различные техники промптинга, которые выходят за рамки базовых методов взаимодействия. Оно исследует методологии для структурирования сложных запросов, улучшения способностей модели к рассуждению, контроля форматов вывода и интеграции внешней информации. Эти техники применимы для создания широкого спектра приложений, от простых чат-ботов до сложных мультиагентных систем, и могут улучшить производительность и надежность агентных приложений.
Агентные паттерны, архитектурные структуры для создания интеллектуальных систем, подробно описаны в основных главах. Эти паттерны определяют, как агенты планируют, используют инструменты, управляют памятью и сотрудничают. Эффективность этих агентных систем зависит от их способности осмысленно взаимодействовать с языковыми моделями.
Основные принципы промптинга
Основные принципы эффективного промптинга языковых моделей:
Эффективный промптинг основывается на фундаментальных принципах, направляющих общение с языковыми моделями, применимых к различным моделям и сложности задач. Освоение этих принципов необходимо для последовательной генерации полезных и точных ответов.
Ясность и специфичность: Инструкции должны быть однозначными и точными. Языковые модели интерпретируют паттерны; множественные интерпретации могут привести к нежелательным ответам. Определите задачу, желаемый формат вывода и любые ограничения или требования. Избегайте расплывчатых формулировок или предположений. Неадекватные промпты дают неоднозначные и неточные ответы, препятствуя осмысленному выводу.
Краткость: Хотя специфичность критически важна, она не должна компрометировать краткость. Инструкции должны быть прямыми. Ненужные формулировки или сложные структуры предложений могут запутать модель или затенить основную инструкцию. Промпты должны быть простыми; то, что сбивает с толку пользователя, скорее всего, сбивает с толку и модель. Избегайте замысловатых выражений и излишней информации. Используйте прямые фразы и активные глаголы для четкого обозначения желаемого действия. Эффективные глаголы включают: Действуй, Анализируй, Категоризируй, Классифицируй, Сравни, Сопоставь, Создай, Опиши, Определи, Оцени, Извлеки, Найди, Генерируй, Идентифицируй, Перечисли, Измерь, Организуй, Разбери, Выбери, Предскажи, Предоставь, Ранжируй, Рекомендуй, Верни, Получи, Перепиши, Выдели, Покажи, Сортируй, Суммируй, Переведи, Напиши.
Использование глаголов: Выбор глагола является ключевым инструментом промптинга. Глаголы действия указывают на ожидаемую операцию. Вместо "Подумай о резюмировании этого" более эффективна прямая инструкция типа "Резюмируй следующий текст". Точные глаголы направляют модель на активацию релевантных обучающих данных и процессов для этой конкретной задачи.
Инструкции вместо ограничений: Позитивные инструкции обычно более эффективны, чем негативные ограничения. Указание желаемого действия предпочтительнее описания того, чего не следует делать. Хотя ограничения имеют свое место для безопасности или строгого форматирования, чрезмерная зависимость от них может заставить модель сосредоточиться на избегании, а не на цели. Формулируйте промпты для прямого направления модели. Позитивные инструкции соответствуют предпочтениям человеческого руководства и уменьшают путаницу.
Экспериментирование и итерация: Prompt engineering — это итеративный процесс. Определение наиболее эффективного промпта требует множественных попыток. Начните с черновика, протестируйте его, проанализируйте вывод, выявите недостатки и усовершенствуйте промпт. Вариации моделей, конфигурации (такие как temperature или top-p) и незначительные изменения формулировок могут дать разные результаты. Документирование попыток жизненно важно для обучения и улучшения. Экспериментирование и итерация необходимы для достижения желаемой производительности.
Эти принципы формируют основу эффективного общения с языковыми моделями. Приоритизируя ясность, краткость, глаголы действия, позитивные инструкции и итерацию, устанавливается надежная основа для применения более продвинутых техник промптинга.
Базовые техники промптинга
Основываясь на ключевых принципах, фундаментальные техники предоставляют языковым моделям различные уровни информации или примеров для направления их ответов. Эти методы служат начальной фазой в prompt engineering и эффективны для широкого спектра приложений.
Zero-Shot промптинг
Zero-shot промптинг является самой базовой формой промптинга, где языковая модель получает инструкцию и входные данные без каких-либо примеров желаемой пары вход-выход. Она полностью полагается на предварительное обучение модели для понимания задачи и генерации релевантного ответа. По сути, zero-shot промпт состоит из описания задачи и начального текста для запуска процесса.
- Когда использовать: Zero-shot промптинг часто достаточен для задач, с которыми модель, вероятно, часто сталкивалась во время обучения, таких как простые вопросы-ответы, завершение текста или базовое резюмирование несложного текста. Это самый быстрый подход для первой попытки.
- Пример:
Переведи следующее английское предложение на французский: 'Hello, how are you?'
One-Shot промптинг
One-shot промптинг включает предоставление языковой модели одного примера входных данных и соответствующего желаемого выходного результата перед представлением фактической задачи. Этот метод служит в качестве первоначальной демонстрации для иллюстрации паттерна, который модель должна воспроизвести. Цель состоит в том, чтобы снабдить модель конкретным экземпляром, который она может использовать в качестве шаблона для эффективного выполнения данной задачи.
Когда использовать: One-shot промптинг полезен, когда желаемый формат вывода или стиль специфичен или менее распространен. Он дает модели конкретный экземпляр для изучения. Может улучшить производительность по сравнению с zero-shot для задач, требующих определенной структуры или тона.
Пример:
Переведи следующие английские предложения на испанский:
English: 'Thank you.'
Spanish: 'Gracias.'English: 'Please.'
Spanish:
Few-Shot промптинг
Few-shot промптинг улучшает one-shot промптинг, предоставляя несколько примеров, обычно от трех до пяти, пар вход-выход. Это направлено на демонстрацию более четкого паттерна ожидаемых ответов, повышая вероятность того, что модель воспроизведет этот паттерн для новых входных данных. Этот метод предоставляет множественные примеры для направления модели следовать определенному паттерну вывода.
Когда использовать: Few-shot промптинг особенно эффективен для задач, где желаемый вывод требует соблюдения определенного формата, стиля или демонстрации нюансированных вариаций. Он отлично подходит для задач классификации, извлечения данных с определенными схемами или генерации текста в определенном стиле, особенно когда zero-shot или one-shot не дают последовательных результатов. Использование как минимум трех-пяти примеров является общим правилом, корректируемым в зависимости от сложности задачи и лимитов токенов модели.
Важность качества и разнообразия примеров: Эффективность few-shot промптинга сильно зависит от качества и разнообразия предоставленных примеров. Примеры должны быть точными, репрезентативными для задачи и охватывать потенциальные вариации или крайние случаи, с которыми модель может столкнуться. Высококачественные, хорошо написанные примеры критически важны; даже небольшая ошибка может запутать модель и привести к нежелательному выводу. Включение разнообразных примеров помогает модели лучше обобщать на невиданные входные данные.
Смешивание классов в примерах классификации: При использовании few-shot промптинга для задач классификации (где модель должна категоризировать входные данные в предопределенные классы), лучшей практикой является смешивание порядка примеров из разных классов. Это предотвращает потенциальное переобучение модели на определенную последовательность примеров и обеспечивает изучение ключевых характеристик каждого класса независимо, что приводит к более надежной и обобщаемой производительности на невиданных данных.
Эволюция к "Many-Shot" обучению: По мере того как современные LLM, такие как Gemini, становятся сильнее в моделировании длинного контекста, они становятся высокоэффективными в использовании "many-shot" обучения. Это означает, что оптимальная производительность для сложных задач теперь может быть достигнута включением гораздо большего количества примеров — иногда даже сотен — непосредственно в промпт, позволяя модели изучать более сложные паттерны.
Пример:
Классифицируй настроение следующих отзывов о фильмах как ПОЛОЖИТЕЛЬНОЕ, НЕЙТРАЛЬНОЕ или ОТРИЦАТЕЛЬНОЕ:Отзыв: "Актерская игра была превосходной, а сюжет увлекательным."
Настроение: ПОЛОЖИТЕЛЬНОЕОтзыв: "Было нормально, ничего особенного."
Настроение: НЕЙТРАЛЬНОЕОтзыв: "Я нашел сюжет запутанным, а персонажей неприятными."
Настроение: ОТРИЦАТЕЛЬНОЕОтзыв: "Визуальные эффекты были потрясающими, но диалоги слабыми."
Настроение:
Понимание того, когда применять zero-shot, one-shot и few-shot техники промптинга, а также продуманное создание и организация примеров, необходимы для повышения эффективности агентных систем. Эти базовые методы служат основой для различных стратегий промптинга.
Структурирование промптов
Помимо базовых техник предоставления примеров, способ структурирования промпта играет критическую роль в направлении языковой модели. Структурирование включает использование различных секций или элементов в промпте для предоставления отдельных типов информации, таких как инструкции, контекст или примеры, в ясной и организованной манере. Это помогает модели правильно разобрать промпт и понять конкретную роль каждой части текста.
Системное промптинг
Системное промптинг устанавливает общий контекст и цель для языковой модели, определяя ее предполагаемое поведение для взаимодействия или сессии. Это включает предоставление инструкций или фоновой информации, которые устанавливают правила, персону или общее поведение. В отличие от конкретных пользовательских запросов, системный промпт предоставляет фундаментальные руководящие принципы для ответов модели. Он влияет на тон, стиль и общий подход модели на протяжении всего взаимодействия. Например, системный промпт может инструктировать модель последовательно отвечать кратко и полезно или обеспечивать соответствие ответов общей аудитории. Системные промпты также используются для контроля безопасности и токсичности путем включения руководящих принципов, таких как поддержание уважительного языка.
Кроме того, для максимизации их эффективности системные промпты могут проходить автоматическую оптимизацию через итеративное усовершенствование на основе LLM. Сервисы, такие как Vertex AI Prompt Optimizer, облегчают это путем систематического улучшения промптов на основе пользовательских метрик и целевых данных, обеспечивая максимально возможную производительность для данной задачи.
- Пример:
Ты полезный и безвредный ИИ-ассистент. Отвечай на все запросы вежливо и информативно. Не генерируй контент, который является вредным, предвзятым или неподходящим.
Ролевое промптинг
Ролевое промптинг назначает конкретного персонажа, персону или идентичность языковой модели, часто в сочетании с системным или контекстуальным промптингом. Это включает инструктирование модели принять знания, тон и стиль общения, связанные с этой ролью. Например, промпты типа "Действуй как туристический гид" или "Ты эксперт по анализу данных" направляют модель отражать перспективу и экспертизу назначенной роли. Определение роли предоставляет рамки для тона, стиля и сфокусированной экспертизы, направленные на улучшение качества и релевантности вывода. Желаемый стиль в рамках роли также может быть указан, например, "юмористический и вдохновляющий стиль".
- Пример:
Действуй как опытный туристический блогер. Напиши короткий, увлекательный абзац о лучшей скрытой жемчужине в Риме.
Использование разделителей
Эффективное промптинг включает четкое различение инструкций, контекста, примеров и входных данных для языковых моделей. Разделители, такие как тройные обратные кавычки (```), XML-теги (<instruction>, <context>) или маркеры (---), могут использоваться для визуального и программного разделения этих секций. Эта практика, широко используемая в prompt engineering, минимизирует неправильную интерпретацию моделью, обеспечивая ясность относительно роли каждой части промпта.
- Пример:
[Вставь полный текст статьи здесь]
Контекстное инжиниринг
Контекстное инжиниринг, в отличие от статических системных промптов, динамически предоставляет фоновую информацию, критически важную для задач и разговоров. Эта постоянно изменяющаяся информация помогает моделям понимать нюансы, запоминать прошлые взаимодействия и интегрировать релевантные детали, что приводит к обоснованным ответам и более плавным обменам. Примеры включают предыдущий диалог, релевантные документы (как в Retrieval Augmented Generation) или специфические операционные параметры. Например, при обсуждении поездки в Японию можно попросить три семейных активности в Токио, используя существующий разговорный контекст. В агентных системах контекстное инжиниринг является фундаментальным для основных поведений агента, таких как сохранение памяти, принятие решений и координация между подзадачами. Агенты с динамическими контекстуальными конвейерами могут поддерживать цели во времени, адаптировать стратегии и беспрепятственно сотрудничать с другими агентами или инструментами — качества, необходимые для долгосрочной автономности. Эта методология утверждает, что качество вывода модели зависит больше от богатства предоставленного контекста, чем от архитектуры модели. Она означает значительную эволюцию от традиционного prompt engineering, который в первую очередь фокусировался на оптимизации формулировки непосредственных пользовательских запросов. Контекстное инжиниринг расширяет свою область, включая множественные слои информации.
Эти слои включают:
- Системные промпты: Фундаментальные инструкции, которые определяют операционные параметры ИИ (например, "Ты технический писатель; твой тон должен быть формальным и точным").
- Внешние данные:
- Полученные документы: Информация, активно извлеченная из базы знаний для информирования ответов (например, получение технических спецификаций).
- Выходы инструментов: Результаты от ИИ, использующего внешний API для данных в реальном времени (например, запрос календаря на доступность).
- Неявные данные: Критическая информация, такая как идентичность пользователя, история взаимодействий и состояние окружения. Включение неявного контекста представляет вызовы, связанные с конфиденциальностью и этическим управлением данными. Поэтому надежное управление необходимо для контекстного инжиниринга, особенно в секторах, таких как предприятия, здравоохранение и финансы.
Основной принцип заключается в том, что даже продвинутые модели показывают низкую производительность с ограниченным или плохо сконструированным представлением их операционной среды. Эта практика переформулирует задачу от простого ответа на вопрос к построению всеобъемлющей операционной картины для агента. Например, агент с контекстным инжинирингом интегрировал бы доступность календаря пользователя (вывод инструмента), профессиональные отношения с получателем электронной почты (неявные данные) и заметки с предыдущих встреч (полученные документы) перед ответом на запрос. Это позволяет модели генерировать высокорелевантные, персонализированные и прагматически полезные выходы. Аспект "инжиниринга" включает создание надежных конвейеров для получения и трансформации этих данных во время выполнения и установление циклов обратной связи для постоянного улучшения качества контекста.
Для реализации этого специализированные системы настройки, такие как оптимизатор промптов Vertex AI от Google, могут автоматизировать процесс улучшения в масштабе. Систематически оценивая ответы на основе образцов входных данных и предопределенных метрик, эти инструменты могут улучшить производительность модели и адаптировать промпты и системные инструкции для разных моделей без обширного ручного переписывания. Предоставление оптимизатору образцов промптов, системных инструкций и шаблона позволяет ему программно усовершенствовать контекстуальные входы, предлагая структурированный метод для реализации необходимых циклов обратной связи для сложного контекстного инжиниринга.
Этот структурированный подход отличает рудиментарный ИИ-инструмент от более сложной, контекстуально-осведомленной системы. Он рассматривает контекст как основной компонент, подчеркивая то, что агент знает, когда он это знает и как он использует эту информацию. Эта практика обеспечивает, чтобы модель имела всестороннее понимание намерений пользователя, истории и текущей среды. В конечном счете, контекстное инжиниринг является критически важной методологией для трансформации безстатусных чат-ботов в высокоспособные, ситуационно-осведомленные системы.
Структурированный вывод
Часто цель промптинга заключается не только в получении свободного текстового ответа, но в извлечении или генерации информации в определенном, машиночитаемом формате. Запрос структурированного вывода, такого как JSON, XML, CSV или Markdown-таблицы, является критически важной техникой структурирования. Явно запрашивая вывод в определенном формате и потенциально предоставляя схему или пример желаемой структуры, вы направляете модель организовать свой ответ способом, который может быть легко разобран и использован другими частями вашей агентной системы или приложения. Возврат JSON-объектов для извлечения данных полезен, поскольку заставляет модель создавать структуру и может ограничивать галлюцинации. Рекомендуется экспериментировать с форматами вывода, особенно для некреативных задач, таких как извлечение или категоризация данных.
Пример:
Извлеки следующую информацию из текста ниже и верни ее как JSON-объект с ключами "name", "address" и "phone_number".Текст: "Свяжитесь с Иваном Смирновым по адресу ул. Главная, 123, Любой город, или звоните (555) 123-4567."
Эффективное использование системных промптов, назначения ролей, контекстуальной информации, разделителей и структурированного вывода значительно улучшает ясность, контроль и полезность взаимодействий с языковыми моделями, обеспечивая прочную основу для разработки надежных агентных систем. Запрос структурированного вывода критически важен для создания конвейеров, где вывод языковой модели служит входом для последующих системных или обрабатывающих шагов.
Использование Pydantic для объектно-ориентированного фасада
Мощная техника для принуждения структурированного вывода и улучшения интероперабельности заключается в использовании сгенерированных LLM данных для заполнения экземпляров объектов Pydantic. Pydantic — это Python-библиотека для валидации данных и управления настройками, использующая аннотации типов Python. Определяя модель Pydantic, вы создаете ясную и принудительную схему для желаемой структуры данных. Этот подход эффективно предоставляет объектно-ориентированный фасад выводу промпта, трансформируя сырой текст или полуструктурированные данные в валидированные, типизированные Python-объекты.
Вы можете напрямую разобрать JSON-строку от LLM в объект Pydantic, используя метод model_validate_json. Это особенно полезно, поскольку объединяет парсинг и валидацию в одном шаге.
from pydantic import BaseModel, EmailStr, Field, ValidationError
from typing import List, Optional
from datetime import date
# --- Определение модели Pydantic ---
class User(BaseModel):
name: str = Field(..., description="Полное имя пользователя.")
email: EmailStr = Field(..., description="Email-адрес пользователя.")
date_of_birth: Optional[date] = Field(None, description="Дата рождения пользователя.")
interests: List[str] = Field(default_factory=list, description="Список интересов пользователя.")
# --- Гипотетический вывод LLM ---
llm_output_json = """
{
"name": "Алиса Иванова",
"email": "alice.i@example.com",
"date_of_birth": "1995-07-21",
"interests": [
"Обработка естественного языка",
"Программирование на Python",
"Садоводство"
]
}
"""
# --- Парсинг и валидация ---
try:
# Используем метод класса model_validate_json для парсинга JSON-строки.
# Этот единственный шаг парсит JSON и валидирует данные согласно модели User.
user_object = User.model_validate_json(llm_output_json)
# Теперь вы можете работать с чистым, типобезопасным Python-объектом.
print("Успешно создан объект User!")
print(f"Имя: {user_object.name}")
print(f"Email: {user_object.email}")
print(f"Дата рождения: {user_object.date_of_birth}")
print(f"Первый интерес: {user_object.interests[0]}")
# Вы можете получать доступ к данным как к любому другому атрибуту Python-объекта.
# Pydantic уже преобразовал строку 'date_of_birth' в объект datetime.date.
print(f"Тип date_of_birth: {type(user_object.date_of_birth)}")
except ValidationError as e:
# Если JSON неправильно сформирован или данные не соответствуют типам модели,
# Pydantic выбросит ValidationError.
print("Не удалось валидировать JSON от LLM.")
print(e)Этот Python-код демонстрирует, как использовать библиотеку Pydantic для определения модели данных и валидации JSON-данных. Он определяет модель User с полями для имени, email, даты рождения и интересов, включая подсказки типов и описания. Код затем парсит гипотетический JSON-вывод от Large Language Model (LLM), используя метод model_validate_json модели User. Этот метод обрабатывает как JSON-парсинг, так и валидацию данных согласно структуре и типам модели. Наконец, код получает доступ к валидированным данным из результирующего Python-объекта и включает обработку ошибок для ValidationError в случае невалидного JSON.
Для XML-данных библиотека xmltodict может использоваться для конвертации XML в словарь, который затем может быть передан модели Pydantic для парсинга. Используя псевдонимы Field в вашей модели Pydantic, вы можете беспрепятственно сопоставить часто многословную или богатую атрибутами структуру XML с полями вашего объекта.
Эта методология неоценима для обеспечения интероперабельности LLM-компонентов с другими частями более крупной системы. Когда вывод LLM инкапсулирован в объект Pydantic, он может быть надежно передан другим функциям, API или конвейерам обработки данных с уверенностью, что данные соответствуют ожидаемой структуре и типам. Эта практика "парсить, не валидировать" на границах компонентов вашей системы приводит к более надежным и поддерживаемым приложениям.
Техники рассуждения и мыслительных процессов
Большие языковые модели превосходят в распознавании паттернов и генерации текста, но часто сталкиваются с вызовами в задачах, требующих сложного, многоэтапного рассуждения. Данное приложение фокусируется на техниках, разработанных для улучшения этих способностей к рассуждению путем побуждения моделей раскрывать свои внутренние мыслительные процессы. В частности, оно рассматривает методы для улучшения логической дедукции, математических вычислений и планирования.
Chain of Thought (CoT)
Техника Chain of Thought (CoT) промптинга является мощным методом для улучшения способностей к рассуждению языковых моделей путем явного побуждения модели генерировать промежуточные шаги рассуждения перед получением окончательного ответа. Вместо простого запроса результата, вы инструктируете модель "думать пошагово". Этот процесс отражает то, как человек может разбить проблему на более мелкие, управляемые части и проработать их последовательно.
CoT помогает LLM генерировать более точные ответы, особенно для задач, требующих некоторой формы вычисления или логической дедукции, где модели в противном случае могли бы испытывать трудности и производить неправильные результаты. Генерируя эти промежуточные шаги, модель с большей вероятностью остается на правильном пути и выполняет необходимые операции корректно.
Существуют две основные вариации CoT:
Zero-Shot CoT: Это включает простое добавление фразы "Давайте думать пошагово" (или аналогичной формулировки) к вашему промпту без предоставления каких-либо примеров процесса рассуждения. Удивительно, но для многих задач это простое добавление может значительно улучшить производительность модели, запуская ее способность раскрывать внутренний след рассуждения.
- Пример (Zero-Shot CoT):
Если поезд движется со скоростью 60 миль в час и покрывает расстояние 240 миль, сколько времени заняла поездка? Давайте думать пошагово.
- Пример (Zero-Shot CoT):
Few-Shot CoT: Это объединяет CoT с few-shot промптингом. Вы предоставляете модели несколько примеров, где показаны входные данные, пошаговый процесс рассуждения и окончательный вывод. Это дает модели более ясный шаблон для выполнения рассуждения и структурирования ответа, часто приводя к еще лучшим результатам на более сложных задачах по сравнению с zero-shot CoT.
Пример (Few-Shot CoT):
В: Сумма трех последовательных целых чисел равна 36. Какие это числа?
О: Пусть первое целое число будет x. Следующее последовательное целое число — x+1, а третье — x+2. Сумма равна x + (x+1) + (x+2) = 3x + 3. Мы знаем, что сумма равна 36, поэтому 3x + 3 = 36. Вычитаем 3 с обеих сторон: 3x = 33. Делим на 3: x = 11. Числа: 11, 11+1=12 и 11+2=13. Числа: 11, 12 и 13.В: У Сары есть 5 яблок, и она покупает еще 8. Она съедает 3 яблока. Сколько яблок у неё осталось? Давайте думать пошагово.
О: Давайте думать пошагово. Сара начинает с 5 яблок. Она покупает еще 8, поэтому добавляет 8 к своему первоначальному количеству: 5 + 8 = 13 яблок. Затем она съедает 3 яблока, поэтому вычитаем 3 из общего количества: 13 - 3 = 10. У Сары осталось 10 яблок. Ответ: 10.
CoT предлагает несколько преимуществ. Его относительно легко реализовать и он может быть высокоэффективным с готовыми LLM без необходимости тонкой настройки. Значительное преимущество — увеличенная интерпретируемость вывода модели; вы можете видеть шаги рассуждения, которые она выполнила, что помогает понять, почему она пришла к определенному ответу и отладить, если что-то пошло не так. Кроме того, CoT повышает надежность промптов для разных версий языковых моделей, что означает, что производительность с меньшей вероятностью ухудшится при обновлении модели. Основным недостатком является то, что генерация шагов рассуждения увеличивает длину вывода, приводя к более высокому использованию токенов, что может увеличить затраты и время ответа.
Лучшие практики для CoT включают обеспечение представления окончательного ответа после шагов рассуждения, поскольку генерация рассуждения влияет на последующие предсказания токенов для ответа. Также для задач с единственным правильным ответом (например, математических задач) рекомендуется установить temperature модели на 0 (жадное декодирование) при использовании CoT для обеспечения детерминированного выбора наиболее вероятного следующего токена на каждом шаге.
Self-Consistency
Основываясь на идее Chain of Thought, техника Self-Consistency направлена на улучшение надежности рассуждения путем использования вероятностной природы языковых моделей. Вместо полагания на единственный жадный путь рассуждения (как в базовом CoT), Self-Consistency генерирует множественные разнообразные пути рассуждения для одной и той же проблемы и затем выбирает наиболее последовательный ответ среди них.
Self-Consistency включает три основных шага:
- Генерация разнообразных путей рассуждения: Один и тот же промпт (часто CoT промпт) отправляется LLM множественное количество раз. Используя более высокую настройку temperature, модель побуждается исследовать различные подходы к рассуждению и генерировать разнообразные пошаговые объяснения.
- Извлечение ответа: Окончательный ответ извлекается из каждого из сгенерированных путей рассуждения.
- Выбор наиболее распространенного ответа: Выполняется голосование большинством по извлеченным ответам. Ответ, который появляется наиболее часто среди разнообразных путей рассуждения, выбирается как окончательный, наиболее последовательный ответ.
Этот подход улучшает точность и связность ответов, особенно для задач, где могут существовать множественные валидные пути рассуждения или где модель может быть склонна к ошибкам в единственной попытке. Преимущество заключается в псевдо-вероятностной оценке корректности ответа, увеличивая общую точность. Однако значительная стоимость — необходимость запускать модель множественное количество раз для одного и того же запроса, что приводит к гораздо более высоким вычислительным затратам и расходам.
- Пример (концептуальный):
- Промпт: "Является ли утверждение 'Все птицы могут летать' истинным или ложным? Объясни свое рассуждение."
- Запуск модели 1 (высокая temp): Рассуждает о большинстве летающих птиц, заключает Истина.
- Запуск модели 2 (высокая temp): Рассуждает о пингвинах и страусах, заключает Ложь.
- Запуск модели 3 (высокая temp): Рассуждает о птицах в общем, кратко упоминает исключения, заключает Истина.
- Результат Self-Consistency: На основе голосования большинством (Истина появляется дважды), окончательный ответ "Истина". (Примечание: более сложный подход взвешивал бы качество рассуждения).
Step-Back промптинг
Step-back промптинг улучшает рассуждение, сначала побуждая языковую модель рассмотреть общий принцип или концепцию, связанную с задачей, перед рассмотрением конкретных деталей. Ответ на этот более широкий вопрос затем используется как контекст для решения исходной проблемы.
Этот процесс позволяет языковой модели активировать релевантные фоновые знания и более широкие стратегии рассуждения. Сосредоточившись на основных принципах или абстракциях более высокого уровня, модель может генерировать более точные и проницательные ответы, менее подверженные влиянию поверхностных элементов. Первоначальное рассмотрение общих факторов может обеспечить более сильную основу для генерации конкретных творческих выходов. Step-back промптинг поощряет критическое мышление и применение знаний, потенциально смягчая предвзятости путем акцента на общих принципах.
- Пример:
- Промпт 1 (Step-Back): "Какие ключевые факторы делают хорошую детективную историю?"
- Ответ модели 1: (Перечисляет элементы, такие как ложные улики, убедительный мотив, порочный протагонист, логические подсказки, удовлетворительная развязка).
- Промпт 2 (исходная задача + контекст Step-Back): "Используя ключевые факторы хорошей детективной истории [вставить ответ модели 1 здесь], напиши краткое резюме сюжета для нового детективного романа, действие которого происходит в маленьком городе."
Tree of Thoughts (ToT)
Tree of Thoughts (ToT) — это продвинутая техника рассуждения, которая расширяет метод Chain of Thought. Она позволяет языковой модели исследовать множественные пути рассуждения одновременно, вместо следования единственной линейной прогрессии. Эта техника использует древовидную структуру, где каждый узел представляет "мысль" — связную языковую последовательность, действующую как промежуточный шаг. Из каждого узла модель может разветвляться, исследуя альтернативные пути рассуждения.
ToT особенно подходит для сложных проблем, требующих исследования, возврата назад или оценки множественных возможностей перед получением решения. Хотя более вычислительно затратный и сложный для реализации, чем линейный метод Chain of Thought, ToT может достигать превосходных результатов на задачах, требующих обдуманного и исследовательского решения проблем. Он позволяет агенту рассматривать разнообразные перспективы и потенциально восстанавливаться от первоначальных ошибок путем исследования альтернативных ветвей в "дереве мыслей".
- Пример (концептуальный): Для сложной задачи творческого письма, такой как "Разработай три различных возможных окончания для истории на основе этих сюжетных точек", ToT позволил бы модели исследовать отдельные нарративные ветви от ключевой поворотной точки, а не просто генерировать одно линейное продолжение.
Эти техники рассуждения и мыслительных процессов критически важны для создания агентов, способных справляться с задачами, выходящими за рамки простого извлечения информации или генерации текста. Побуждая модели раскрывать свое рассуждение, рассматривать множественные перспективы или отступать к общим принципам, мы можем значительно улучшить их способность выполнять сложные когнитивные задачи в агентных системах.
Техники действий и взаимодействия
Интеллектуальные агенты обладают способностью активно взаимодействовать со своей средой, выходя за рамки генерации текста. Это включает использование инструментов, выполнение внешних функций и участие в итеративных циклах наблюдения, рассуждения и действия. Данный раздел рассматривает техники промптинга, разработанные для обеспечения этих активных поведений.
Использование инструментов / Вызов функций
Критически важная способность для агента — использование внешних инструментов или вызов функций для выполнения действий, выходящих за рамки его внутренних возможностей. Эти действия могут включать веб-поиск, доступ к базам данных, отправку электронных писем, выполнение вычислений или взаимодействие с внешними API. Эффективный промптинг для использования инструментов включает разработку промптов, которые инструктируют модель о подходящем времени и методологии использования инструментов.
Современные языковые модели часто проходят тонкую настройку для "вызова функций" или "использования инструментов". Это позволяет им интерпретировать описания доступных инструментов, включая их назначение и параметры. При получении пользовательского запроса модель может определить необходимость использования инструмента, идентифицировать подходящий инструмент и отформатировать требуемые аргументы для его вызова. Модель не выполняет инструмент напрямую. Вместо этого она генерирует структурированный вывод, обычно в формате JSON, указывающий инструмент и его параметры. Агентная система затем обрабатывает этот вывод, выполняет инструмент и предоставляет результат инструмента обратно модели, интегрируя его в продолжающееся взаимодействие.
Пример:
У тебя есть доступ к инструменту погоды, который может получить текущую погоду для указанного города. Инструмент называется 'get_current_weather' и принимает параметр 'city' (строка).Пользователь: Какая сейчас погода в Лондоне?
- Ожидаемый вывод модели (вызов функции):json
{ "tool_code": "get_current_weather", "tool_name": "get_current_weather", "parameters": { "city": "London" } }
- Ожидаемый вывод модели (вызов функции):
ReAct (Reason & Act)
ReAct, сокращение от Reason and Act, — это парадигма промптинга, которая объединяет рассуждение в стиле Chain of Thought со способностью выполнять действия с использованием инструментов в чередующейся манере. ReAct имитирует то, как работают люди — мы рассуждаем вербально и предпринимаем действия для сбора дополнительной информации или продвижения к цели.
Паттерн ReAct включает цикл:
- Мысль: Модель генерирует мыслительный процесс, объясняя свое текущее понимание и план.
- Действие: На основе мысли модель решает выполнить действие, часто используя инструмент (например, Поиск, Калькулятор, вызов API). Она выводит название инструмента и требуемый вход.
- Наблюдение: Агентная система выполняет инструмент и предоставляет результат (Наблюдение) обратно модели.
- Цикл продолжается с генерацией модели новой "Мысли" на основе последнего "Наблюдения", ведущей к дальнейшим "Действиям" и "Наблюдениям" до завершения задачи и вывода модели "Окончательного ответа".
Этот чередующийся процесс мышления и действия позволяет агенту динамически собирать информацию, реагировать на выводы инструментов и уточнять свой подход, делая его особенно эффективным для задач, требующих взаимодействия с динамическими средами или внешними источниками знаний.
Пример (иллюстративный след ReAct):
Пользователь: Какая столица Франции и какое её текущее население?Мысль: Пользователь спрашивает две части информации: столицу Франции и её население. Я могу использовать инструмент поиска для поиска этой информации. Начну с подтверждения столицы, хотя я, вероятно, знаю её.
Действие: Search({"query": "столица Франции"})
Наблюдение: ПарижМысль: Хорошо, столица — Париж. Теперь мне нужно найти население Парижа.
Действие: Search({"query": "текущее население Парижа"})
Наблюдение: Население Парижа оценивалось примерно в 2,1 миллиона человек в 2023 году.Мысль: Я нашел обе части информации. Теперь могу предоставить окончательный ответ пользователю.
Окончательный ответ: Столица Франции — Париж, и её оценочное население в 2023 году составляло около 2,1 миллиона человек.
Эти техники жизненно важны для создания агентов, которые могут активно взаимодействовать с миром, получать информацию в реальном времени и выполнять задачи, требующие взаимодействия с внешними системами.
Продвинутые техники
Помимо фундаментальных, структурных и рассуждающих паттернов, существует несколько других техник промптинга, которые могут дополнительно улучшить возможности и эффективность агентных систем. Они варьируются от использования ИИ для оптимизации промптов до включения внешних знаний и адаптации ответов на основе характеристик пользователя.
Автоматическое Prompt Engineering (APE)
Признавая, что создание эффективных промптов может быть сложным и итеративным процессом, Автоматическое Prompt Engineering (APE) исследует использование самих языковых моделей для генерации, оценки и усовершенствования промптов. Этот метод направлен на автоматизацию процесса написания промптов, потенциально улучшая производительность модели без требования обширных человеческих усилий в дизайне промптов.
Общая идея заключается в том, чтобы иметь "мета-модель" или процесс, который берет описание задачи и генерирует множественные кандидаты промптов. Эти промпты затем оцениваются на основе качества вывода, который они производят на данном наборе входных данных (возможно, используя метрики, такие как BLEU или ROUGE, или человеческую оценку). Наиболее производительные промпты могут быть выбраны, потенциально дополнительно усовершенствованы и использованы для целевой задачи. Использование LLM для генерации вариаций пользовательского запроса для обучения чат-бота является примером этого.
- Пример (концептуальный): Разработчик предоставляет описание: "Мне нужен промпт, который может извлекать дату и отправителя из электронного письма." Система APE генерирует несколько кандидатов промптов. Они тестируются на образцах электронных писем, и промпт, который последовательно извлекает правильную информацию, выбирается.
Другая мощная техника оптимизации промптов, особенно продвигаемая фреймворком DSPy, включает рассмотрение промптов не как статического текста, но как программных модулей, которые могут быть автоматически оптимизированы. Этот подход выходит за рамки ручного метода проб и ошибок к более систематической, управляемой данными методологии.
Ядро этой техники опирается на два ключевых компонента:
- Goldset (или высококачественный набор данных): Это репрезентативный набор высококачественных пар вход-выход. Он служит "золотым стандартом", который определяет, как выглядит успешный ответ для данной задачи.
- Объективная функция (или метрика оценки): Это функция, которая автоматически оценивает вывод LLM против соответствующего "золотого" вывода из набора данных. Она возвращает оценку, указывающую качество, точность или корректность ответа.
Используя эти компоненты, оптимизатор, такой как байесовский оптимизатор, систематически усовершенствует промпт. Этот процесс обычно включает две основные стратегии, которые могут использоваться независимо или совместно:
- Оптимизация few-shot примеров: Вместо ручного выбора разработчиком примеров для few-shot промпта, оптимизатор программно сэмплирует различные комбинации примеров из goldset. Затем он тестирует эти комбинации для идентификации конкретного набора примеров, который наиболее эффективно направляет модель к генерации желаемых выходов.
- Оптимизация инструкционного промпта: В этом подходе оптимизатор автоматически усовершенствует основные инструкции промпта. Он использует LLM как "мета-модель" для итеративного изменения и переформулировки текста промпта — корректируя формулировки, тон или структуру — для обнаружения того, какая формулировка дает наивысшие оценки от объективной функции.
Конечная цель для обеих стратегий — максимизировать оценки от объективной функции, эффективно "тренируя" промпт для производства результатов, которые последовательно ближе к высококачественному goldset. Объединяя эти два подхода, система может одновременно оптимизировать какие инструкции давать модели и какие примеры ей показывать, приводя к высокоэффективному и надежному промпту, который машинно-оптимизирован для конкретной задачи.
Итеративное промптинг / Усовершенствование
Эта техника включает начало с простого, базового промпта и затем итеративное его усовершенствование на основе первоначальных ответов модели. Если вывод модели не совсем правильный, вы анализируете недостатки и модифицируете промпт для их устранения. Это менее автоматизированный процесс (в отличие от APE) и более управляемый человеком итеративный цикл дизайна.
- Пример:
- Попытка 1: "Напиши описание продукта для нового типа кофеварки." (Результат слишком общий).
- Попытка 2: "Напиши описание продукта для нового типа кофеварки. Подчеркни её скорость и легкость очистки." (Результат лучше, но не хватает деталей).
- Попытка 3: "Напиши описание продукта для 'SpeedClean Coffee Pro'. Подчеркни её способность варить кофе менее чем за 2 минуты и её самоочищающийся цикл. Ориентируйся на занятых профессионалов." (Результат гораздо ближе к желаемому).
Предоставление негативных примеров
Хотя принцип "Инструкции вместо ограничений" в целом верен, есть ситуации, где предоставление негативных примеров может быть полезным, хотя используется осторожно. Негативный пример показывает модели вход и нежелательный вывод, или вход и вывод, который не должен быть сгенерирован. Это может помочь прояснить границы или предотвратить определенные типы неправильных ответов.
Пример:
Сгенерируй список популярных туристических достопримечательностей в Париже. НЕ включай Эйфелеву башню.Пример того, что НЕ делать:
Вход: Перечисли популярные достопримечательности в Париже.
Вывод: Эйфелева башня, Лувр, Собор Парижской Богоматери.
Использование аналогий
Формулировка задачи с использованием аналогии иногда может помочь модели понять желаемый вывод или процесс, соотнося его с чем-то знакомым. Это может быть особенно полезно для творческих задач или объяснения сложных ролей.
- Пример:
Действуй как "шеф-повар данных". Возьми сырые ингредиенты (точки данных) и приготовь "блюдо-резюме" (отчет), которое подчеркивает ключевые вкусы (тренды) для бизнес-аудитории.
Факторизованное познание / Декомпозиция
Для очень сложных задач может быть эффективно разбить общую цель на более мелкие, управляемые подзадачи и промптить модель отдельно для каждой подзадачи. Результаты подзадач затем объединяются для достижения окончательного результата. Это связано с цепочкой промптов и планированием, но подчеркивает обдуманную декомпозицию проблемы.
- Пример: Для написания исследовательской работы:
- Промпт 1: "Сгенерируй подробный план для статьи о влиянии ИИ на рынок труда."
- Промпт 2: "Напиши раздел введения на основе этого плана: [вставить план введения]."
- Промпт 3: "Напиши раздел 'Влияние на работников умственного труда' на основе этого плана: [вставить раздел плана]." (Повторить для других разделов).
- Промпт N: "Объедини эти разделы и напиши заключение."
Retrieval Augmented Generation (RAG)
RAG — это мощная техника, которая улучшает языковые модели, предоставляя им доступ к внешней, актуальной или доменно-специфической информации во время процесса промптинга. Когда пользователь задает вопрос, система сначала извлекает релевантные документы или данные из базы знаний (например, базы данных, набора документов, веба). Эта извлеченная информация затем включается в промпт как контекст, позволяя языковой модели генерировать ответ, основанный на этих внешних знаниях. Это смягчает проблемы, такие как галлюцинации, и предоставляет доступ к информации, на которой модель не была обучена или которая очень свежая. Это ключевой паттерн для агентных систем, которые должны работать с динамической или проприетарной информацией.
- Пример:
- Запрос пользователя: "Какие новые функции в последней версии Python-библиотеки 'X'?"
- Действие системы: Поиск в базе данных документации "Python библиотека X последние функции".
- Промпт для LLM: "На основе следующих фрагментов документации: [вставить извлеченный текст], объясни новые функции в последней версии Python-библиотеки 'X'."
Паттерн персоны (пользовательская персона)
В то время как ролевое промптинг назначает персону модели, паттерн персоны включает описание пользователя или целевой аудитории для вывода модели. Это помогает модели адаптировать свой ответ с точки зрения языка, сложности, тона и типа информации, которую она предоставляет.
Пример:
Ты объясняешь квантовую физику. Целевая аудитория — старшеклассник без предварительных знаний по предмету. Объясни это просто и используй аналогии, которые они могут понять.Объясни квантовую физику: [Вставить запрос базового объяснения]
Эти продвинутые и дополнительные техники предоставляют дополнительные инструменты для prompt-инженеров для оптимизации поведения модели, интеграции внешней информации и адаптации взаимодействий для конкретных пользователей и задач в агентных рабочих процессах.
Использование Google Gems
"Gems" от Google (см. Рис. 1) представляют пользовательскую настраиваемую функцию в архитектуре больших языковых моделей. Каждый "Gem" функционирует как специализированный экземпляр основного ИИ Gemini, адаптированный для конкретных, повторяемых задач. Пользователи создают Gem, предоставляя ему набор явных инструкций, которые устанавливают его операционные параметры. Этот начальный набор инструкций определяет назначенную цель Gem, стиль ответа и область знаний. Базовая модель разработана для последовательного соблюдения этих предопределенных директив на протяжении разговора.
Это позволяет создавать высокоспециализированных ИИ-агентов для сфокусированных приложений. Например, Gem может быть настроен для функционирования как интерпретатор кода, который ссылается только на определенные библиотеки программирования. Другой может быть инструктирован анализировать наборы данных, генерируя резюме без спекулятивных комментариев. Различный Gem может служить как переводчик, придерживающийся определенного формального руководства по стилю. Этот процесс создает постоянный, специфичный для задачи контекст для искусственного интеллекта.
Следовательно, пользователь избегает необходимости переустанавливать одну и ту же контекстуальную информацию с каждым новым запросом. Эта методология уменьшает разговорную избыточность и улучшает эффективность выполнения задач. Результирующие взаимодействия более сфокусированы, давая выходы, которые последовательно соответствуют первоначальным требованиям пользователя. Эта структура позволяет применять тонкое, постоянное пользовательское руководство к модели ИИ общего назначения. В конечном счете, Gems позволяют переход от взаимодействия общего назначения к специализированным, предопределенным функциональностям ИИ.
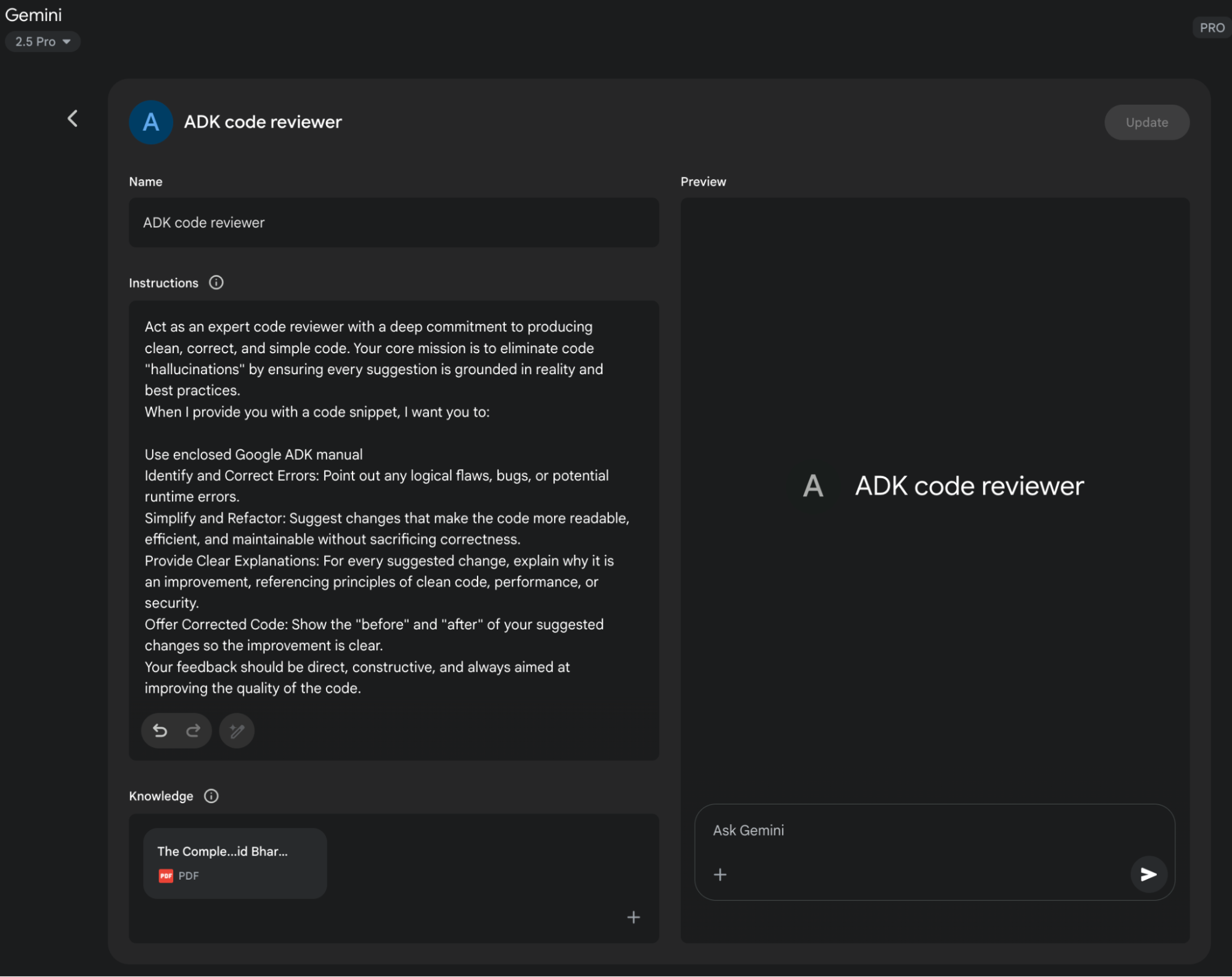
Рис.1: Пример использования Google Gem.
Использование LLM для улучшения промптов (Мета-подход)
Мы изучили множественные техники для создания эффективных промптов, подчеркивая ясность, структуру и предоставление контекста или примеров. Этот процесс, однако, может быть итеративным и иногда сложным. Что если мы могли бы использовать саму мощь больших языковых моделей, таких как Gemini, чтобы помочь нам улучшить наши промпты? Это суть использования LLM для усовершенствования промптов — "мета"-применение, где ИИ помогает в оптимизации инструкций, данных ИИ.
Эта способность особенно "крута", потому что она представляет форму самоулучшения ИИ или, по крайней мере, ИИ-ассистированного человеческого улучшения во взаимодействии с ИИ. Вместо полагания исключительно на человеческую интуицию и метод проб и ошибок, мы можем использовать понимание LLM языка, паттернов и даже распространенных подводных камней промптинга для получения предложений по улучшению наших промптов. Это превращает LLM в коллаборативного партнера в процессе prompt engineering.
Как это работает на практике? Вы можете предоставить языковой модели существующий промпт, который пытаетесь улучшить, вместе с задачей, которую хотите выполнить, и возможно даже примеры вывода, который получаете в настоящее время (и почему он не соответствует вашим ожиданиям). Затем вы промптите LLM проанализировать промпт и предложить улучшения.
Модель, такая как Gemini, с её сильными способностями к рассуждению и генерации языка, может анализировать ваш существующий промпт на потенциальные области неоднозначности, отсутствие специфичности или неэффективную формулировку. Она может предложить включение техник, которые мы обсуждали, таких как добавление разделителей, прояснение желаемого формата вывода, предложение более эффективной персоны или рекомендация включения few-shot примеров.
Преимущества этого мета-промптинг подхода включают:
- Ускоренная итерация: Получение предложений по улучшению гораздо быстрее, чем чистый ручной метод проб и ошибок.
- Идентификация слепых зон: LLM может заметить неоднозначности или потенциальные неправильные интерпретации в вашем промпте, которые вы упустили.
- Возможность обучения: Видя типы предложений, которые делает LLM, вы можете узнать больше о том, что делает промпты эффективными, и улучшить свои собственные навыки prompt engineering.
- Масштабируемость: Потенциально автоматизировать части процесса оптимизации промптов, особенно при работе с большим количеством промптов.
Важно отметить, что предложения LLM не всегда идеальны и должны оцениваться и тестироваться, как любой вручную созданный промпт. Однако это предоставляет мощную отправную точку и может значительно упростить процесс усовершенствования.
Пример промпта для усовершенствования:
Проанализируй следующий промпт для языковой модели и предложи способы его улучшения для последовательного извлечения основной темы и ключевых сущностей (люди, организации, локации) из новостных статей. Текущий промпт иногда пропускает сущности или неправильно определяет основную тему.Существующий промпт:
"Резюмируй основные пункты и перечисли важные имена и места из этой статьи: [вставить текст статьи]"Предложения по улучшению:
В этом примере мы используем LLM для критики и улучшения другого промпта. Это мета-уровневое взаимодействие демонстрирует гибкость и мощь этих моделей, позволяя нам создавать более эффективные агентные системы путем сначала оптимизации фундаментальных инструкций, которые они получают. Это захватывающий цикл, где ИИ помогает нам лучше говорить с ИИ.
Промптинг для специфических задач
Хотя техники, обсуждаемые до сих пор, широко применимы, некоторые задачи получают выгоду от специфических соображений промптинга. Они особенно релевантны в области кода и мультимодальных входных данных.
Промптинг кода
Языковые модели, особенно те, которые обучены на больших наборах данных кода, могут быть мощными помощниками для разработчиков. Промптинг для кода включает использование LLM для генерации, объяснения, перевода или отладки кода. Существуют различные случаи использования:
Промпты для написания кода: Запрос модели генерировать фрагменты кода или функции на основе описания желаемой функциональности.
- Пример: "Напиши Python-функцию, которая принимает список чисел и возвращает среднее значение."
Промпты для объяснения кода: Предоставление фрагмента кода и запрос модели объяснить, что он делает, построчно или в резюме.
- Пример: "Объясни следующий JavaScript-фрагмент кода: [вставить код]."
Промпты для перевода кода: Запрос модели перевести код с одного языка программирования на другой.
- Пример: "Переведи следующий Java-код на C++: [вставить код]."
Промпты для отладки и рецензирования кода: Предоставление кода, который имеет ошибку или может быть улучшен, и запрос модели идентифицировать проблемы, предложить исправления или предоставить предложения по рефакторингу.
- Пример: "Следующий Python-код дает 'NameError'. Что не так и как это можно исправить? [вставить код и трассировку]."
Эффективный промптинг кода часто требует предоставления достаточного контекста, указания желаемого языка и версии, и ясности относительно функциональности или проблемы.
Мультимодальный промптинг
Хотя фокус этого приложения и большая часть текущего взаимодействия с LLM основана на тексте, область быстро движется к мультимодальным моделям, которые могут обрабатывать и генерировать информацию через различные модальности (текст, изображения, аудио, видео и т.д.). Мультимодальный промптинг включает использование комбинации входных данных для направления модели. Это относится к использованию множественных форматов входных данных вместо только текста.
- Пример: Предоставление изображения диаграммы и запрос модели объяснить процесс, показанный на диаграмме (Ввод изображения + Текстовый промпт). Или предоставление изображения и запрос модели сгенерировать описательную подпись (Ввод изображения + Текстовый промпт → Текстовый вывод).
По мере того как мультимодальные возможности становятся более сложными, техники промптинга будут эволюционировать для эффективного использования этих комбинированных входных и выходных данных.
Лучшие практики и эксперименты
Становление квалифицированным prompt-инженером — это итеративный процесс, который включает непрерывное обучение и эксперименты. Несколько ценных лучших практик стоит повторить и подчеркнуть:
- Предоставляй примеры: Предоставление one-shot или few-shot примеров — один из наиболее эффективных способов направить модель.
- Дизайн с простотой: Держи свои промпты краткими, ясными и легкими для понимания. Избегай ненужного жаргона или чрезмерно сложных формулировок.
- Будь специфичен относительно вывода: Четко определи желаемый формат, длину, стиль и содержание ответа модели.
- Используй инструкции вместо ограничений: Сосредоточься на том, чтобы сказать модели, что ты хочешь, чтобы она делала, а не на том, чего ты не хочешь, чтобы она делала.
- Контролируй максимальную длину токенов: Используй конфигурации модели или явные инструкции промпта для управления длиной генерируемого вывода.
- Используй переменные в промптах: Для промптов, используемых в приложениях, используй переменные, чтобы сделать их динамическими и переиспользуемыми, избегая жесткого кодирования специфических значений.
- Экспериментируй с форматами ввода и стилями письма: Попробуй различные способы формулировки своего промпта (вопрос, утверждение, инструкция) и экспериментируй с различными тонами или стилями, чтобы увидеть, что дает лучшие результаты.
- Для few-shot промптинга с задачами классификации смешивай классы: Рандомизируй порядок примеров из различных категорий, чтобы предотвратить переобучение.
- Адаптируйся к обновлениям модели: Языковые модели постоянно обновляются. Будь готов тестировать существующие промпты на новых версиях модели и корректировать их для использования новых возможностей или поддержания производительности.
- Экспериментируй с форматами вывода: Особенно для некреативных задач экспериментируй с запросом структурированного вывода, такого как JSON или XML.
- Экспериментируй совместно с другими prompt-инженерами: Сотрудничество с другими может предоставить различные перспективы и привести к обнаружению более эффективных промптов.
- Лучшие практики CoT: Помни специфические практики для Chain of Thought, такие как размещение ответа после рассуждения и установка temperature на 0 для задач с единственным правильным ответом.
- Документируй различные попытки промптов: Это критически важно для отслеживания того, что работает, что не работает и почему. Поддерживай структурированную запись своих промптов, конфигураций и результатов.
- Сохраняй промпты в кодовых базах: При интеграции промптов в приложения храни их в отдельных, хорошо организованных файлах для более легкого обслуживания и контроля версий.
- Полагайся на автоматизированные тесты и оценку: Для производственных систем внедри автоматизированные тесты и процедуры оценки для мониторинга производительности промптов и обеспечения обобщения на новые данные.
Prompt engineering — это навык, который улучшается с практикой. Применяя эти принципы и техники и поддерживая систематический подход к экспериментам и документации, ты можешь значительно улучшить свою способность создавать эффективные агентные системы.
Заключение
Данное приложение предоставляет всеобъемлющий обзор промптинга, переформулируя его как дисциплинированную инженерную практику, а не простой акт задавания вопросов. Его центральная цель — продемонстрировать, как трансформировать языковые модели общего назначения в специализированные, надежные и высокоспособные инструменты для конкретных задач. Путь начинается с непререкаемых основных принципов, таких как ясность, краткость и итеративные эксперименты, которые являются краеугольным камнем эффективного общения с ИИ. Эти принципы критически важны, поскольку они уменьшают присущую естественному языку неоднозначность, помогая направить вероятностные выходы модели к единственному, правильному намерению. Основываясь на этом фундаменте, базовые техники, такие как zero-shot, one-shot и few-shot промптинг, служат основными методами для демонстрации ожидаемого поведения через примеры. Эти методы предоставляют различные уровни контекстуального руководства, мощно формируя стиль ответа модели, тон и формат. Помимо простых примеров, структурирование промптов с явными ролями, системными инструкциями и четкими разделителями предоставляет существенный архитектурный слой для тонкого контроля над моделью.
Важность этих техник становится первостепенной в контексте создания автономных агентов, где они обеспечивают контроль и надежность, необходимые для сложных, многошаговых операций. Чтобы агент эффективно создавал и выполнял план, он должен использовать продвинутые паттерны рассуждения, такие как Chain of Thought и Tree of Thoughts. Эти сложные методы заставляют модель экстернализировать свои логические шаги, систематически разбивая сложные цели на последовательность управляемых подзадач. Операционная надежность всей агентной системы зависит от предсказуемости каждого компонентного вывода. Именно поэтому запрос структурированных данных, таких как JSON, и программная их валидация с помощью инструментов, таких как Pydantic, является не просто удобством, но абсолютной необходимостью для надежной автоматизации. Без этой дисциплины внутренние когнитивные компоненты агента не могут надежно общаться, что приводит к катастрофическим сбоям в автоматизированном рабочем процессе. В конечном счете, эти техники структурирования и рассуждения успешно конвертируют вероятностную генерацию текста модели в детерминированный и заслуживающий доверия когнитивный движок для агента.
Кроме того, эти промпты предоставляют агенту критически важную способность воспринимать и воздействовать на свою среду, преодолевая разрыв между цифровой мыслью и взаимодействием с реальным миром. Ориентированные на действие фреймворки, такие как ReAct и нативный вызов функций, являются жизненно важными механизмами, которые служат руками агента, позволяя ему использовать инструменты, запрашивать API и манипулировать данными. Параллельно техники, такие как Retrieval Augmented Generation (RAG) и более широкая дисциплина контекстного инжиниринга, функционируют как чувства агента. Они активно извлекают релевантную, актуальную информацию из внешних баз знаний, обеспечивая, что решения агента основаны на текущей, фактической реальности. Эта критически важная способность предотвращает работу агента в вакууме, где он был бы ограничен своими статическими и потенциально устаревшими обучающими данными. Освоение этого полного спектра промптинга является, таким образом, определяющим навыком, который возвышает языковую модель общего назначения от простого генератора текста до истинно сложного агента, способного выполнять сложные задачи с автономностью, осведомленностью и интеллектом.
Ссылки
Вот список ресурсов для дальнейшего чтения и более глубокого изучения техник prompt engineering:
- Prompt Engineering
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- Self-Consistency Improves Chain of Thought Reasoning in Language Models
- ReAct: Synergizing Reasoning and Acting in Language Models
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
- DSPy: Programming—not prompting—Foundation Models https://github.com/stanfordnlp/dspy
Навигация
Назад: Глава 21. Исследование и открытие
Вперед: Приложение B. Агентные взаимодействия ИИ от GUI до реального мира